
Данные привычно воспринимаются как цифры, но в книге «Тёмные данные» Дэвид Хэнд приравнивает к ним ошибку в названии винтажного пива и даже мошенничество. Понимаем, за всеми тёмными данными не угнаться. Но если знать, как они возникают, меньше шанс совершить ошибку и больше вероятность трезво оценить ситуацию.
«Данные, которых у вас нет, могут быть важнее для понимания реальности, чем те, которыми вы располагаете» – так описал ахиллесову пяту в науке профессор математики и сотрудник Имперского коллежда в Лондоне. В своей книге Хэнд выделяет 15 типов тёмных данных, нехватка которых может привести к искажениям, неверным выводам и ошибкам в восприятии ситуации.
«Данные, которых у вас нет, могут быть важнее для понимания реальности, чем те, которыми вы располагаете» – так описал ахиллесову пяту в науке профессор математики и сотрудник Имперского коллежда в Лондоне. В своей книге Хэнд выделяет 15 типов тёмных данных, нехватка которых может привести к искажениям, неверным выводам и ошибкам в восприятии ситуации.

DD-тип 1: Данные, о которых мы знаем, что они существуют. Это самый очевидный тип, который возникает, когда не хватает переменных и возникают пропуски.
DD-тип 2: Данные, о которых мы не знаем, что они существуют. Потому что не догадываемся, что забыли их измерить.
DD-тип 3: Выборочные факты. Когда мы судим о явлениях только на основе личного опыта.
DD-тип 4: Самоотбор. Источники данных сами решают, стоит ли их предоставлять.
DD-тип 5: Неизвестный определяющий фактор. Отсутствие данных приводит к ложным причинно-следственным связям.
DD-тип 6: Данные, которые могли бы существовать. Как поведение людей меняется в зависимости от его условий.
DD-тип 7: Данные, которые меняются со временем. Данные больше не отражают текущую ситуацию.
DD-тип 8: Данные, которые неверно определили. Например, формальная фиксация семьи не учитывает, как могут складываться отношения в ней
DD-тип 9: Обобщение. Даже расчёт распределений скрывает их особенности.
DD-тип 10: Ошибки измерения и неопределённость
DD-тип 11: Искажения обратной связи. Закон Кэмпбелла: чем шире используется количественный показатель, тем сильнее он искажает социальные процессы.
DD-тип 12: Асимметрия информации. Не все знают все - одна сторона скрывает данные от другой.
DD-тип 13: Намеренно затемнённые данные. Например, с целью мошенничества.
DD-тип 14: Фальшивые данные. Например, фейк-ньюс. Или синтетические данные, которые возникают при сглаживании и допущениях в статистике.
DD-тип 15: Экстраполяция за пределы ваших данных. Работа с данными может привести к их затемнению при округлении, ошибках ввода, объединении наборов с разным числом наблюдений.
Примеры работы с тёмными данными
DD-тип 2: Данные, о которых мы не знаем, что они существуют. Потому что не догадываемся, что забыли их измерить.
DD-тип 3: Выборочные факты. Когда мы судим о явлениях только на основе личного опыта.
DD-тип 4: Самоотбор. Источники данных сами решают, стоит ли их предоставлять.
DD-тип 5: Неизвестный определяющий фактор. Отсутствие данных приводит к ложным причинно-следственным связям.
DD-тип 6: Данные, которые могли бы существовать. Как поведение людей меняется в зависимости от его условий.
DD-тип 7: Данные, которые меняются со временем. Данные больше не отражают текущую ситуацию.
DD-тип 8: Данные, которые неверно определили. Например, формальная фиксация семьи не учитывает, как могут складываться отношения в ней
DD-тип 9: Обобщение. Даже расчёт распределений скрывает их особенности.
DD-тип 10: Ошибки измерения и неопределённость
DD-тип 11: Искажения обратной связи. Закон Кэмпбелла: чем шире используется количественный показатель, тем сильнее он искажает социальные процессы.
DD-тип 12: Асимметрия информации. Не все знают все - одна сторона скрывает данные от другой.
DD-тип 13: Намеренно затемнённые данные. Например, с целью мошенничества.
DD-тип 14: Фальшивые данные. Например, фейк-ньюс. Или синтетические данные, которые возникают при сглаживании и допущениях в статистике.
DD-тип 15: Экстраполяция за пределы ваших данных. Работа с данными может привести к их затемнению при округлении, ошибках ввода, объединении наборов с разным числом наблюдений.
Примеры работы с тёмными данными

На самом деле, владельцы дорогих авто с акселерометрами живут в богатых районах - данные оттуда будут неполными. Оказалось, что главная причина ухабов - утопленные крышки люков, а не выбоины.
Приложение Street Bump. Его разработала мэрия Бостона для автомобилистов, которые должны фиксировать на смартфоне каждую встряску на дорогах.
Приложение Street Bump. Его разработала мэрия Бостона для автомобилистов, которые должны фиксировать на смартфоне каждую встряску на дорогах.
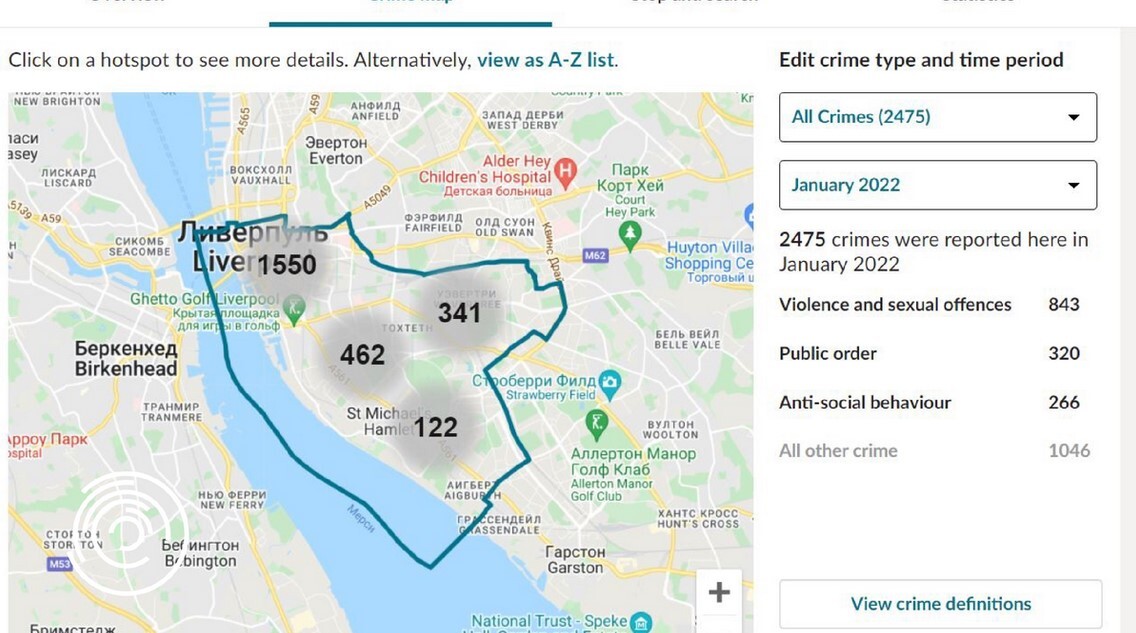
Вместо мест с инцидентами карты показывают районы, где люди готовы о них сообщить.
Опрос Direct Line Home Insurance. Страховая компания выяснила, 11% респондентов не заявляют о том, что видели преступления, потому что опасались, что данные на картах преступности отпугнут арендаторов жилья в их районе.
«Если любую информацию принимать за данные, её анализ становится сложным». В конце своей книги математик и статистик Дэвид Хэнд описывает принципы работы с тёмными данными. В них речь идёт не просто об информации, а наборе сведений о совокупности объектов.
Учёный раскрывает механизмы появления недостающих данных:
- UDD (Unseen Data Dependent) - потерянные данные зависят от невидимых. Вероятность того, что наблюдений окажется недостаточно, зависит от значений, которые ещё неизвестны. Их можно было бы измерить, если бы все «дошли» до конца периода наблюдения.
- SDD (Seen Data Dependent) - потерянные наблюдения, которые зависят от видимых данных. Вероятность того, что наблюдений не хватит для прогноза, зависит от данных, которые не зафиксировали в начале исследования.
- NDD (Not Data Dependent) - потерянные наблюдения не зависят от имеющихся или отсутствующих данных Выпадение в этой группе не связаны с факторами видимости данных. Как правило, наблюдений недостаточно по причинам, которые никак не связаны с исследованием. Это самая простая ситуация, и вероятно, самая редкая. Здесь тёмные данные не имеют значения.

Как работать с SDD и UDD:
«Тёмные данные» помогают систематизировать инструменты «подозрительного» отношения к данным.
- SDD - коварные, но не безнадёжные потери. Например, по оставшимся наблюдениям можно смоделировать, как связаны значения в начале (t1) и в конце (t2) исследования. А для потерянных данных рассчитать значения переменных в t2 по начальным в t1.
- UDD - действительно сложная группа причин. Хэнк так оценивает возможности анализа: «Единственный способ оценить такие данные - получить информацию откуда-то ещё или предположить самому, почему именно эти значения отсутствуют. ... В случае с категорией UDD нам нужно искать решение в другом месте».
«Тёмные данные» помогают систематизировать инструменты «подозрительного» отношения к данным.

Ставьте реакции, если материал интересный. Поделимся новыми источниками в принятии решений.
Если хотите самостоятельно управлять даже тёмными данными, приглашаем на обучение: https://base-line.ru/consal.
Если хотите самостоятельно управлять даже тёмными данными, приглашаем на обучение: https://base-line.ru/consal.








